Đó là khá nhiều những gì bạn nói. Chính thức bạn có thể nói:
Phương sai, trong ngữ cảnh của Machine Learning, là một loại lỗi xảy ra do độ nhạy của mô hình đối với các dao động nhỏ trong tập huấn luyện.
Phương sai cao sẽ gây ra một thuật toán mô hình nhiễu trong tập huấn luyện. Điều này thường được gọi là quá mức .
Khi thảo luận về phương sai trong Machine Learning, chúng tôi cũng đề cập đến xu hướng .
Bias, trong ngữ cảnh của Machine Learning, là một loại lỗi xảy ra do các giả định sai lầm trong thuật toán học tập.
Độ lệch cao sẽ khiến thuật toán bỏ lỡ các mối quan hệ liên quan giữa các tính năng đầu vào và đầu ra đích. Điều này đôi khi được gọi là thiếu .
Mối quan hệ giữa sai lệch và phương sai:
Trong hầu hết các trường hợp, cố gắng giảm thiểu một trong hai lỗi này, sẽ dẫn đến việc tăng lỗi kia. Do đó, cả hai thường được coi là một sự đánh đổi .

Nguyên nhân của sai lệch / phương sai cao trong ML:
Yếu tố phổ biến nhất quyết định độ lệch / phương sai của mô hình là khả năng của nó (nghĩ về điều này như mức độ phức tạp của mô hình).
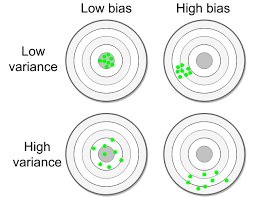
Các mô hình dung lượng thấp (ví dụ hồi quy tuyến tính), có thể bỏ lỡ các mối quan hệ có liên quan giữa các tính năng và mục tiêu, khiến chúng có độ lệch cao. Điều này thể hiện rõ ở hình bên trái.
Mặt khác, các mô hình dung lượng cao (ví dụ hồi quy đa thức bậc cao, mạng nơ ron có nhiều tham số) có thể mô hình một số nhiễu, cùng với bất kỳ mối quan hệ liên quan nào trong tập huấn luyện, khiến chúng có phương sai cao, như đã thấy trong hình bên phải
Làm thế nào để giảm phương sai trong một mô hình?
Cách dễ nhất và phổ biến nhất để giảm phương sai trong mô hình ML là áp dụng các kỹ thuật giới hạn khả năng hiệu quả của nó, tức là chính quy hóa .
Các hình thức chính quy phổ biến nhất là hình phạt định mức tham số , giới hạn các cập nhật tham số trong giai đoạn đào tạo; dừng lại sớm , mà cắt giảm đào tạo ngắn; cắt tỉa cho các thuật toán dựa trên cây; bỏ học cho các mạng thần kinh, vv
Một mô hình có thể có cả sai lệch thấp và phương sai thấp?
Có . Tương tự như vậy, một mô hình có thể có cả độ lệch cao và phương sai cao, như được minh họa trong hình dưới đây.
Làm thế nào chúng ta có thể đạt được cả sai lệch thấp và phương sai thấp?
Trong thực tế phương pháp nhất là:
- Chọn một thuật toán có công suất đủ cao để mô hình hóa đủ vấn đề. Trong giai đoạn này, chúng tôi muốn giảm thiểu sai lệch , vì vậy chúng tôi chưa quan tâm đến phương sai.
- Thường xuyên mô hình ở trên, để giảm thiểu phương sai của nó .