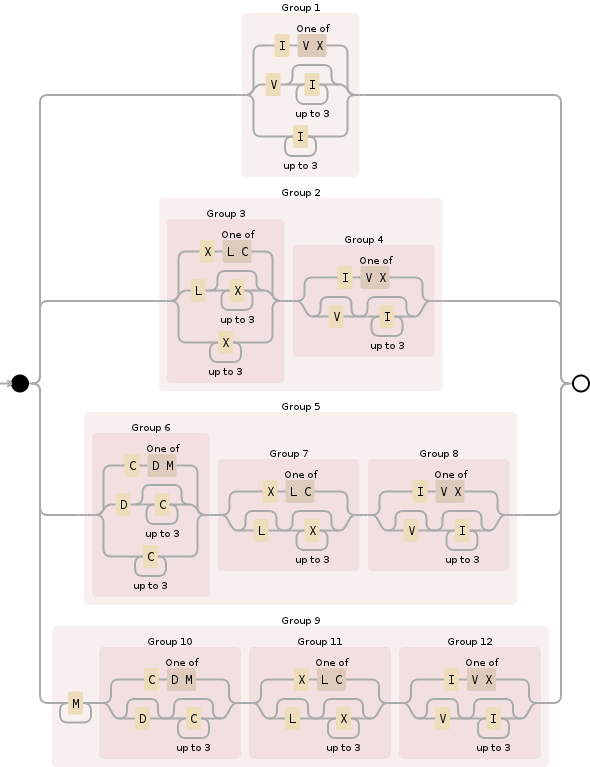
Bạn có thể sử dụng regex sau đây cho việc này:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Phá vỡ nó, M{0,4}chỉ định phần ngàn và về cơ bản hạn chế nó ở giữa 0và 4000. Nó tương đối đơn giản:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Tất nhiên, bạn có thể sử dụng một cái gì đó như M*để cho phép bất kỳ số nào (bao gồm số không) trong số hàng ngàn, nếu bạn muốn cho phép số lớn hơn.
Tiếp theo (CM|CD|D?C{0,3}), phức tạp hơn một chút, đây là phần trăm và bao gồm tất cả các khả năng:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Thứ ba, (XC|XL|L?X{0,3})tuân theo các quy tắc tương tự như phần trước nhưng đối với vị trí hàng chục:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
Và cuối cùng, (IX|IV|V?I{0,3})là phần đơn vị, xử lý 0xuyên suốt 9và cũng tương tự như hai phần trước (chữ số La Mã, mặc dù có vẻ kỳ lạ, hãy tuân theo một số quy tắc logic khi bạn tìm ra chúng là gì):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Chỉ cần nhớ rằng regex đó cũng sẽ khớp với một chuỗi rỗng. Nếu bạn không muốn điều này (và công cụ regex của bạn đủ hiện đại), bạn có thể sử dụng cái nhìn tích cực và nhìn về phía trước:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(cách khác là chỉ kiểm tra xem độ dài không bằng 0 trước đó).