Câu hỏi này xuất phát từ sự nhầm lẫn thực tế của tôi về cách quyết định xem một mô hình logistic có đủ tốt hay không. Tôi có các mô hình sử dụng trạng thái của các cặp dự án riêng lẻ hai năm sau khi chúng được hình thành như một biến phụ thuộc. Kết quả có thành công (1) hay không (0). Tôi có các biến độc lập được đo tại thời điểm hình thành các cặp. Mục đích của tôi là kiểm tra xem một biến, mà tôi đưa ra giả thuyết có ảnh hưởng đến sự thành công của các cặp có ảnh hưởng đến thành công đó hay không, kiểm soát các ảnh hưởng tiềm năng khác. Trong các mô hình, các biến quan tâm là đáng kể.
Các mô hình đã được ước tính bằng cách sử dụng glm()chức năng trong R. Để đánh giá chất lượng của các mô hình, tôi đã thực hiện một vài điều: glm()cung cấp cho bạn residual deviance, các AICvà BICtheo mặc định. Ngoài ra, tôi đã tính tỷ lệ lỗi của mô hình và vẽ các phần dư có giá trị.
- Mô hình hoàn chỉnh có độ lệch dư nhỏ hơn, AIC và BIC so với các mô hình khác mà tôi đã ước tính (và được lồng trong mô hình hoàn chỉnh), điều này khiến tôi nghĩ rằng mô hình này "tốt hơn" so với các mô hình khác.
- Tỷ lệ lỗi của mô hình khá thấp, IMHO (như trong Gelman và Hill, 2007, tr.99 ) :
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1), ở mức khoảng 20%.
Càng xa càng tốt. Nhưng khi tôi vẽ phần dư còn lại (một lần nữa theo lời khuyên của Gelman và Hill), một phần lớn các thùng nằm ngoài 95% CI:
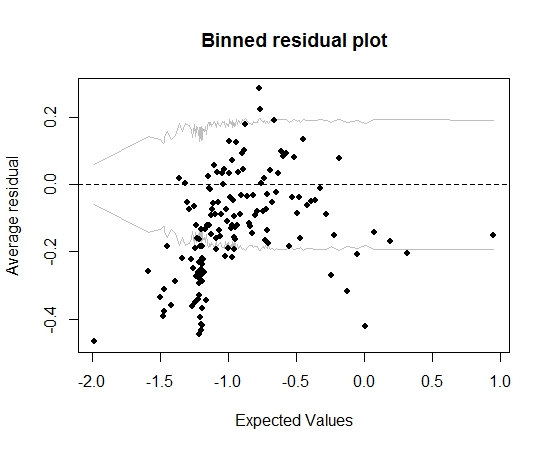
Cốt truyện đó khiến tôi nghĩ rằng có một cái gì đó hoàn toàn sai về mô hình. Điều đó có nên dẫn tôi ném mô hình đi? Tôi có nên thừa nhận rằng mô hình là không hoàn hảo nhưng giữ nó và giải thích ảnh hưởng của biến quan tâm? Tôi đã lần lượt đùa giỡn với việc loại trừ các biến, và một số biến đổi, mà không thực sự cải thiện âm mưu dư thừa.
Biên tập:
- Hiện tại, mô hình có hàng tá dự đoán và 5 hiệu ứng tương tác.
- Các cặp "tương đối" độc lập với nhau theo nghĩa là tất cả chúng được hình thành trong một khoảng thời gian ngắn (nhưng không nói một cách nghiêm túc, tất cả đồng thời) và có rất nhiều dự án (13k) và rất nhiều cá nhân (19k) ), do đó, một tỷ lệ hợp lý các dự án chỉ được tham gia bởi một cá nhân (có khoảng 20000 cặp).