Kiểm tra RTEFC ("Phân cụm bộ lọc theo hàm mũ thời gian thực") hoặc RTMAC ("Phân cụm trung bình di chuyển thời gian thực), là các biến thể K-time hiệu quả, đơn giản, phù hợp để sử dụng theo thời gian thực khi phân cụm nguyên mẫu phù hợp. của vectơ. Xem https://gregstanleyandassociates.com/whitepapers/BDAC/Clustering/clustering.htmlm
và tài liệu liên quan về biểu diễn chuỗi thời gian đa biến như một vectơ lớn hơn ở mỗi bước thời gian (biểu diễn cho "BDAC"), với một slide cửa sổ thời gian.
Chúng được phát triển để đồng thời thực hiện cả việc lọc tiếng ồn và phân cụm trong thời gian thực để nhận biết và theo dõi các điều kiện khác nhau. RTMAC hạn chế sự tăng trưởng bộ nhớ bằng cách giữ lại các quan sát gần đây nhất gần với một cụm nhất định. RTEFC chỉ giữ lại trọng tâm từ bước này sang bước tiếp theo, đủ cho nhiều ứng dụng. Về mặt hình ảnh, RTEFC trông giống như:
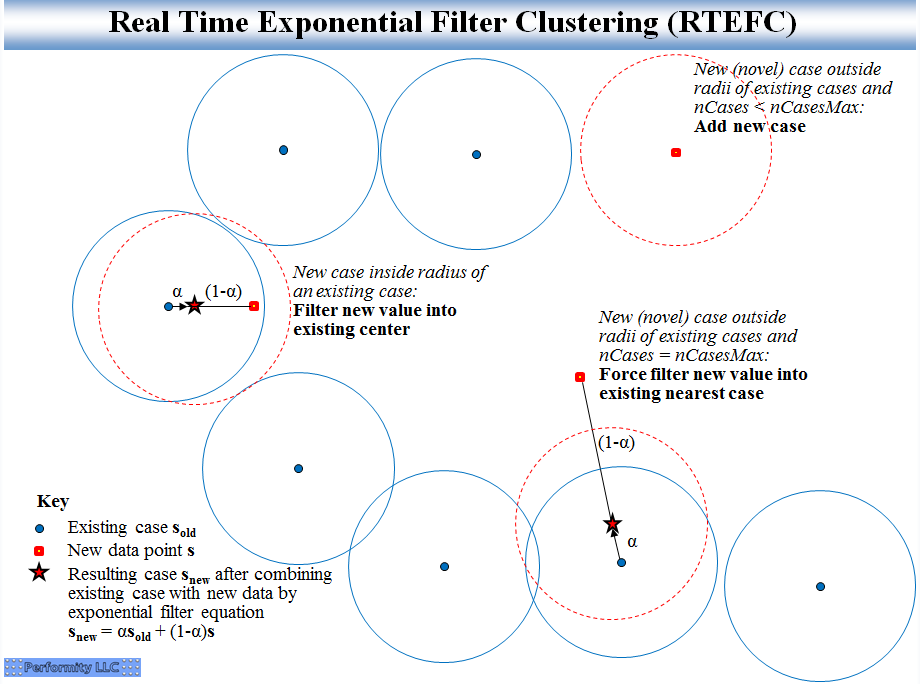
Dawg yêu cầu so sánh điều này với HDBSCAN, đặc biệt là hàm xấp xỉ_predict (). Sự khác biệt chính là HDBSCAN vẫn cho rằng thỉnh thoảng có sự đào tạo lại từ các điểm dữ liệu ban đầu, một hoạt động tốn kém. Hàm HDBSCAN xấp xỉ_predict () được sử dụng để nhận phân công cụm nhanh cho dữ liệu mới mà không cần đào tạo lại. Trong trường hợp RTEFC, không bao giờ có bất kỳ tính toán đào tạo lại lớn nào, bởi vì các điểm dữ liệu gốc không được lưu trữ. Thay vào đó, chỉ có các trung tâm cụm được lưu trữ. Mỗi điểm dữ liệu mới chỉ cập nhật một trung tâm cụm (hoặc tạo một trung tâm mới nếu cần và trong giới hạn trên được chỉ định về số lượng cụm hoặc cập nhật một trung tâm trước đó). Chi phí tính toán ở mỗi bước là thấp và có thể dự đoán được.
Các hình ảnh có một số điểm tương đồng, ngoại trừ hình ảnh HDBSCAN sẽ không có điểm được gắn dấu sao cho biết trung tâm cụm được tính toán lại cho một điểm dữ liệu mới gần một cụm hiện có và hình ảnh HDBSCAN sẽ từ chối trường hợp cụm mới hoặc trường hợp cập nhật bắt buộc là ngoại lệ.
RTEFC cũng được tùy chọn sửa đổi khi quan hệ nhân quả được biết là một tiên nghiệm (khi các hệ thống đã xác định đầu vào và đầu ra). Các đầu vào hệ thống giống nhau (và các điều kiện ban đầu cho các hệ thống động) sẽ tạo ra các đầu ra hệ thống giống nhau. Họ không vì tiếng ồn hoặc thay đổi hệ thống. Trong trường hợp đó, bất kỳ số liệu khoảng cách nào được sử dụng để phân cụm đều được sửa đổi để chỉ tính đến sự gần gũi của các đầu vào hệ thống & điều kiện ban đầu. Vì vậy, do sự kết hợp tuyến tính của các trường hợp lặp đi lặp lại, tiếng ồn bị hủy bỏ một phần và sự thích ứng chậm với các thay đổi hệ thống xảy ra. Các trọng tâm thực sự là đại diện tốt hơn cho hành vi hệ thống điển hình hơn bất kỳ điểm dữ liệu cụ thể nào, vì giảm nhiễu.
Một điểm khác biệt nữa là tất cả những gì đã được phát triển cho RTEFC chỉ là thuật toán cốt lõi. Nó đủ đơn giản để thực hiện chỉ với một vài dòng mã, nhanh và với thời gian tính toán tối đa có thể dự đoán được ở mỗi bước. Điều này khác với toàn bộ cơ sở với rất nhiều lựa chọn. Những thứ đó là phần mở rộng hợp lý. Chẳng hạn, từ chối ngoại lệ, có thể chỉ cần yêu cầu rằng sau một thời gian, các điểm nằm ngoài khoảng cách xác định đến một trung tâm cụm hiện có sẽ bị bỏ qua thay vì được sử dụng để tạo các cụm mới hoặc cập nhật cụm gần nhất.
Mục tiêu của RTEFC là kết thúc với một tập hợp các điểm đại diện xác định hành vi có thể có của một hệ thống được quan sát, thích ứng với các thay đổi của hệ thống theo thời gian và tùy ý giảm ảnh hưởng của tiếng ồn trong các trường hợp lặp lại với nguyên nhân đã biết. Đó không phải là để duy trì tất cả các dữ liệu gốc, một số trong đó có thể trở nên lỗi thời khi hệ thống quan sát thay đổi theo thời gian. Điều này giảm thiểu yêu cầu lưu trữ cũng như thời gian tính toán. Tập hợp các đặc điểm này (trung tâm cụm làm điểm đại diện là tất cả những gì cần thiết, sự thích ứng theo thời gian, thời gian tính toán thấp và có thể dự đoán được) sẽ không phù hợp với tất cả các ứng dụng. Điều này có thể được áp dụng để duy trì các tập dữ liệu đào tạo trực tuyến cho phân cụm theo định hướng hàng loạt, các mô hình gần đúng chức năng mạng thần kinh hoặc sơ đồ khác để phân tích hoặc xây dựng mô hình. Các ứng dụng ví dụ có thể bao gồm phát hiện / chẩn đoán lỗi; kiểm soát quá trình; hoặc những nơi khác mà các mô hình có thể được tạo từ các điểm đại diện hoặc hành vi chỉ được nội suy giữa các điểm đó. Các hệ thống được quan sát sẽ là những hệ thống được mô tả chủ yếu bằng một tập hợp các biến liên tục, có thể yêu cầu mô hình hóa với các phương trình đại số và / hoặc mô hình chuỗi thời gian (bao gồm các phương trình khác biệt / phương trình vi phân), cũng như các ràng buộc bất đẳng thức.