Tôi nhận thức rõ về các ưu điểm của xác thực chéo k-Fold (và bỏ qua một lần), cũng như các ưu điểm của việc tách tập huấn luyện của bạn để tạo tập hợp 'xác thực' thứ ba mà bạn sử dụng để đánh giá hiệu suất mô hình dựa trên các lựa chọn của siêu đường kính, vì vậy bạn có thể tối ưu hóa và điều chỉnh chúng và chọn những cái tốt nhất để cuối cùng được đánh giá trên bộ thử nghiệm thực. Tôi đã thực hiện cả hai điều này một cách độc lập trên các bộ dữ liệu khác nhau.
Tuy nhiên tôi không chắc chắn làm thế nào để tích hợp hai quá trình này. Tôi chắc chắn nhận thức được nó có thể được thực hiện (xác nhận chéo lồng nhau, tôi nghĩ vậy?), Và tôi đã thấy mọi người giải thích nó, nhưng chưa bao giờ đủ chi tiết rằng tôi đã thực sự hiểu các chi tiết của quy trình.
Có những trang với đồ họa thú vị ám chỉ quá trình này (như thế này ) mà không rõ ràng về việc thực hiện chính xác các phần tách và vòng lặp. Ở đây, cái thứ tư rõ ràng là những gì tôi muốn làm, nhưng quá trình không rõ ràng:
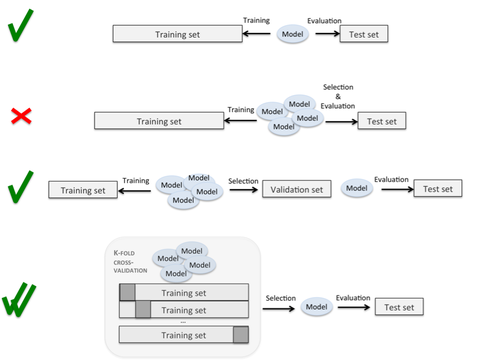
Có những câu hỏi trước đây trên trang web này, nhưng trong khi những câu hỏi nêu lên tầm quan trọng của việc tách các bộ xác nhận khỏi các bộ kiểm tra, thì không có câu hỏi nào chỉ định quy trình chính xác mà việc này nên được thực hiện.
Đây có phải là một cái gì đó giống như: đối với mỗi lần gấp k, hãy coi nếp gấp đó là một bộ thử nghiệm, coi một nếp gấp khác nhau như một bộ xác nhận và huấn luyện trên phần còn lại? Điều này có vẻ như bạn phải lặp đi lặp lại toàn bộ tập dữ liệu k * k lần, để mỗi lần được sử dụng làm đào tạo, kiểm tra và xác nhận ít nhất một lần. Xác thực chéo lồng nhau dường như ngụ ý rằng bạn thực hiện phân tách kiểm tra / xác thực bên trong mỗi nếp gấp k của bạn, nhưng chắc chắn điều này không thể đủ dữ liệu để cho phép điều chỉnh tham số hiệu quả, đặc biệt là khi k cao.
Ai đó có thể giúp tôi bằng cách cung cấp giải thích chi tiết về các vòng lặp và phân tách cho phép xác thực chéo k-gấp (để cuối cùng bạn có thể coi mọi datapoint như một trường hợp thử nghiệm) trong khi thực hiện điều chỉnh tham số (như bạn không chỉ định trước tham số mô hình, và thay vào đó chọn những tham số hoạt động tốt nhất trên một tập hợp giữ riêng biệt)?