Tôi đã có câu hỏi này trong nhiều tháng. Có vẻ như chúng ta chỉ khéo léo đoán softmax là một hàm đầu ra và sau đó diễn giải đầu vào cho softmax là xác suất log. Như bạn đã nói, tại sao không đơn giản hóa bình thường tất cả các kết quả đầu ra bằng cách chia cho tổng của chúng? Tôi đã tìm thấy câu trả lời trong cuốn sách Deep Learning của Goodfellow, Bengio và Courville (2016) trong phần 6.2.2.
Giả sử lớp ẩn cuối cùng của chúng ta cung cấp cho chúng ta z như một kích hoạt. Sau đó, softmax được định nghĩa là

Giải thích rất ngắn
Điểm kinh nghiệm trong hàm softmax gần như hủy bỏ nhật ký trong mất mát entropy chéo làm cho tổn thất gần như tuyến tính trong z_i. Điều này dẫn đến một độ dốc gần như không đổi, khi mô hình sai, cho phép nó tự sửa một cách nhanh chóng. Do đó, một softmax bão hòa sai không gây ra độ dốc biến mất.
Giải thích ngắn
Phương pháp phổ biến nhất để huấn luyện một mạng lưới thần kinh là Ước tính khả năng tối đa. Chúng tôi ước tính các tham số theta theo cách tối đa hóa khả năng của dữ liệu đào tạo (có kích thước m). Bởi vì khả năng của toàn bộ tập dữ liệu đào tạo là sản phẩm của khả năng của từng mẫu, nên việc tối đa hóa khả năng ghi nhật ký của tập dữ liệu sẽ dễ dàng hơn và do đó tổng khả năng ghi nhật ký của từng mẫu được lập chỉ mục bởi k:
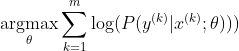
Bây giờ, chúng tôi chỉ tập trung vào softmax ở đây với z đã được cung cấp, vì vậy chúng tôi có thể thay thế
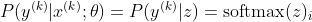
với tôi là lớp chính xác của mẫu thứ k. Bây giờ, chúng ta thấy rằng khi chúng ta lấy logarit của softmax, để tính khả năng đăng nhập của mẫu, chúng ta sẽ nhận được:
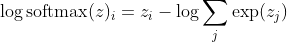
, mà cho sự khác biệt lớn trong z gần như xấp xỉ với
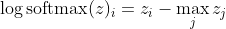
Đầu tiên, chúng ta thấy thành phần tuyến tính z_i ở đây. Thứ hai, chúng ta có thể kiểm tra hành vi của max (z) cho hai trường hợp:
- Nếu mô hình là chính xác, thì max (z) sẽ là z_i. Do đó, khả năng log không có triệu chứng bằng 0 (nghĩa là khả năng 1) với sự khác biệt ngày càng tăng giữa z_i và các mục khác trong z.
- Nếu mô hình không chính xác, thì max (z) sẽ là một số z_j> z_i khác. Vì vậy, việc thêm z_i không hoàn toàn hủy bỏ -z_j và khả năng đăng nhập là khoảng (z_i - z_j). Điều này cho biết rõ mô hình phải làm gì để tăng khả năng đăng nhập: tăng z_i và giảm z_j.
Chúng tôi thấy rằng khả năng đăng nhập tổng thể sẽ bị chi phối bởi các mẫu, trong đó mô hình không chính xác. Ngoài ra, ngay cả khi mô hình thực sự không chính xác, dẫn đến softmax bão hòa, chức năng mất không bão hòa. Nó xấp xỉ tuyến tính trong z_j, có nghĩa là chúng ta có độ dốc gần như không đổi. Điều này cho phép mô hình tự sửa một cách nhanh chóng. Lưu ý rằng đây không phải là trường hợp của Lỗi bình phương trung bình chẳng hạn.
Giải thích dài
Nếu softmax vẫn có vẻ như là một lựa chọn tùy ý cho bạn, bạn có thể xem qua lời biện minh cho việc sử dụng sigmoid trong hồi quy logistic:
Tại sao chức năng sigmoid thay vì bất cứ điều gì khác?
Softmax là sự khái quát của sigmoid cho các vấn đề đa lớp tương tự.



