Chúng là hai số liệu khác nhau để đánh giá hiệu suất mô hình của bạn thường được sử dụng trong các giai đoạn khác nhau.
Mất mát thường được sử dụng trong quá trình đào tạo để tìm các giá trị tham số "tốt nhất" cho mô hình của bạn (ví dụ: trọng số trong mạng thần kinh). Đó là những gì bạn cố gắng tối ưu hóa trong đào tạo bằng cách cập nhật trọng lượng.
Độ chính xác là nhiều hơn từ một quan điểm ứng dụng. Khi bạn tìm thấy các tham số được tối ưu hóa ở trên, bạn sử dụng số liệu này để đánh giá mức độ chính xác của dự đoán mô hình của bạn so với dữ liệu thực.
Hãy để chúng tôi sử dụng một ví dụ phân loại đồ chơi. Bạn muốn dự đoán giới tính từ cân nặng và chiều cao của một người. Bạn có 3 dữ liệu, chúng như sau: (0 là viết tắt của nam, 1 là viết tắt của nữ)
y1 = 0, x1_w = 50kg, x2_h = 160cm;
y2 = 0, x2_w = 60kg, x2_h = 170cm;
y3 = 1, x3_w = 55kg, x3_h = 175cm;
Bạn sử dụng mô hình hồi quy logistic đơn giản đó là y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Làm thế nào để bạn tìm thấy b1 và b2? trước tiên bạn xác định tổn thất và sử dụng phương pháp tối ưu hóa để giảm thiểu tổn thất theo cách lặp bằng cách cập nhật b1 và b2.
Trong ví dụ của chúng tôi, một mất mát điển hình cho vấn đề phân loại nhị phân này có thể là: (một dấu trừ nên được thêm vào trước dấu tổng

Chúng ta không biết b1 và b2 nên là gì. Chúng ta hãy đoán ngẫu nhiên nói b1 = 0,1 và b2 = -0,03. Vậy thì mất mát của chúng ta bây giờ là gì?
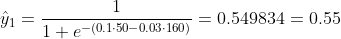
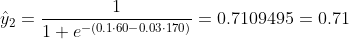
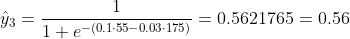
vì vậy mất mát là
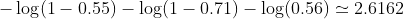
Sau đó, bạn học thuật toán (ví dụ: giảm độ dốc) sẽ tìm cách cập nhật b1 và b2 để giảm tổn thất.
Điều gì xảy ra nếu b1 = 0,1 và b2 = -0,03 là b1 và b2 cuối cùng (đầu ra từ độ dốc giảm dần), độ chính xác bây giờ là bao nhiêu?
Giả sử nếu y_hat> = 0,5, chúng tôi quyết định dự đoán của chúng tôi là nữ (1). nếu không nó sẽ là 0. Do đó, thuật toán của chúng tôi dự đoán y1 = 1, y2 = 1 và y3 = 1. Độ chính xác của chúng tôi là gì? Chúng tôi dự đoán sai về y1 và y2 và đưa ra dự đoán đúng trên y3. Vì vậy, bây giờ độ chính xác của chúng tôi là 1/3 = 33,33%
PS: Trong câu trả lời của Amir , lan truyền ngược được cho là một phương pháp tối ưu hóa trong NN. Tôi nghĩ rằng nó sẽ được coi là một cách để tìm độ dốc cho trọng số trong NN. Phương pháp tối ưu hóa phổ biến trong NN là GradientDescent và Adam.
